 粤公网安备 44011302004783号
粤公网安备 44011302004783号 英伟达Model Optimizer!PTQ模型压缩,N分钟吃透NVFP4量化
对于追求卓越性能和精度的AI开发者来说,模型量化是不可或缺的关键技术。它通过在可控范围内降低模型精度,无需重新训练,就能显著提升推理速度、吞吐量以及内存利用率。
目前,大多数模型采用FP16或BF16精度进行训练,部分模型如DeepSeek-R甚至原生支持FP8。进一步量化到FP4等格式,能够释放更大的效率和性能潜力,而日渐成熟的开源生态系统也为此提供了坚实的技术保障。
英伟达TensorRT模型优化器(Model Optimizer)的后训练量化(PTQ)框架,提供了一种灵活且模块化的方案来实现这些优化。它支持包括为英伟达Blackwell GPU优化的NVFP4在内的多种格式,并集成了SmoothQuant、激活感知权重量化(AWQ)和AutoQuantize等校准技术,以提升量化效果。
Model Optimizer PTQ还具备良好的生态兼容性,原生支持PyTorch、Hugging Face、NeMo和Megatron-LM等检查点,并能与英伟达TensorRT-LLM、vLLM和SGLang等推理框架轻松集成。
本文将深入探讨PTQ技术,并介绍如何使用Model Optimizer PTQ压缩AI模型,同时保持高精度,从而提升用户体验和AI应用性能。
量化技术入门
神经网络由多个层组成,这些层包含的值可以通过模型预训练和后训练过程进行调整,从而学习执行不同的任务。这些学习成果以权重、激活值和偏差的形式存储在不同类型的层中。在实践中,模型通常以全精度(TF32/FP32)、半精度(BF16/FP16)、混合精度以及最近的FP8精度进行训练。训练精度决定了模型的原生精度,直接影响模型推理的计算复杂度和内存需求。
量化技术使我们能够用训练过程中通常不需要的过剩精度,换取更快的推理速度和更小的内存占用。性能提升的幅度取决于我们量化网络的程度、原生精度与量化精度之间的差异,以及我们使用的算法。图1展示了一组高精度权重如何被重新采样和量化。
图1 量化本质上是将值从高精度格式重新采样到低精度格式的过程
通常用于模型训练的32位和16位数据类型可以被量化到8位、4位甚至更低。这个过程包括压缩原始值,使之适应低精度数据类型较小的可表示范围。
在这个量化过程中,值必须适应目标数据类型的可表示范围。在这个适应过程中,值的范围从更精细到更粗略。例如,从FP16到FP8,值A和B在量化后分别表示为QA和QB,但它们之间的距离更远,导致分辨率降低(图2)。
图2 从FP16量化到FP8或FP4时,范围和细节的变化
表1总结了最常用的数据类型的可表示范围。
| 数据类型 | 总位数 | 可表示范围 |
|---|---|---|
| FP32 | 32 | ±3.4 × 10³⁸ |
| FP16 | 16 | ±65,504 |
| BF16 | 16 | ±3.4 × 10³⁸ |
| FP8 | 8 | ±448 |
| FP4 | 4 | -6 to +6 |
| INT8 | 8 | -128 to +127 |
| INT4 | 4 | -8 to +7 |
表1 数据类型、位宽、可表示范围和格式描述(浮点与整数)摘要
量化后的格式将具有以量化格式的范围表示的原始值的版本。这种转换是通过量化比例因子来实现的,该比例因子使用以下公式计算:

其中b是目标字节数,而 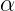

其中X是原始数据类型,而S是比例因子。
图3显示了从FP16转换为FP4的量化过程的结果。FP16值{4.75, 2.01, -3.44, -7.11, 0, 13.43, -4.91, -6.43}在FP4中被量化为{2, 1, -2, -4, 0, 7, -3, -3}。
图3 使用对称静态量化和标准比例因子将FP16值缩减到FP4的示例
有很多技术可以用于调整量化,但本文重点介绍使用Model Optimizer进行有效的PTQ。虽然有很多高级方法,如剪裁、范围映射和校准,但Model Optimizer提供了一个简单的API,可以轻松应用正确的配置。
使用TensorRT Model Optimizer进行PTQ
TensorRT Model Optimizer是一个高级模型优化技术库,专门用于优化模型的推理性能。模型经过优化后,可以使用Dynamo、SGLang、TensorRT-LLM和vLLM等推理框架进行下游部署。
表2总结了Model Optimizer支持的不同量化格式以及简要说明。
| 量化格式 | 描述 |
|---|---|
| Per-Tensor FP8 | 使用默认比例编码的标准全模型FP8量化 |
| FP8 Block-wise Weight Only | 2D块状、仅权重量化。在小块之间共享缩放 |
| FP8 Per Channel and Per Token | Per-channel权重,动态per-token激活量化 |
| nvfp4 | 权重和激活的默认FP4量化 |
| INT8 SmoothQuant | 具有SmoothQuant校准的8位量化。Per-channel权重,per-tensor激活 |
| WA416 (INT4 Weights Only) | 具有AWQ校准的4位仅权重量化。Group-wise/block-wise权重,FP16激活 |
| W4A8 (INT4 Weights, FP8 Activations) | 具有AWQ的4位权重,FP8激活量化。Block-wise权重,per-tensor FP8激活 |
| fp8 (KV) | 启用注意力层中键值缓存的FP8量化 |
| nvfp4 (KV) | 用于transformer注意力层中键值缓存的FP4缓存量化 |
| Nvfp4_affine (KV) | 使用仿射缩放的键值缓存量化 |
表2 Model Optimizer支持的量化格式摘要,按类型(浮点、整数、KV缓存)和描述组织
选择正确的量化格式、KV缓存精度和校准方法取决于您的特定模型和工作负载。Model Optimizer提供了几种技术来帮助您完成此操作,包括:
- Min-max校准
- SmoothQuant
- 激活感知权重量化 (AWQ)
- AutoQuantize
在以下部分中,我们将详细介绍这些技术,并提供动手Jupyter notebook教程,以便您可以学习如何使用Model Optimizer API并将其应用于您自己的模型。
使用min-max校准进行标准量化
在量化模型之前,需要对其进行校准以了解其激活的动态范围。最简单和最常见的校准方法之一是min-max校准。在此过程中,一小部分具有代表性的数据集(校准数据集)通过原始模型以收集激活统计信息。对于每个张量,观察到的最小值和最大值用于确定将浮点值映射到较低精度整数的比例因子。虽然快速且易于应用,但min-max校准对异常值很敏感,并且缺乏更高级技术中使用的自适应缩放。
假设模型和tokenizer已成功加载,则可以使用Model Optimizer提供的get_dataset_dataloader和create_forward_loop实用程序函数来配置校准数据加载器和前向循环。PTQ可以使用小型的校准数据集来应用——通常只有128到512个样本,并且精度通常在不同的数据集中保持稳定。在此示例中,使用数据集cnn_dailymail。可以通过修改get_dataset_dataloader()调用中的dataset_name配置来替换不同的数据集。
# Calibration dataloader
calib_loader = get_dataset_dataloader(
dataset_name=”cnn_dailymail”,
tokenizer=tokenizer,
batch_size=batch_size,
num_samples=calib_samples,
device="cuda"
)
forward_loop = create_forward_loop(dataloader=calib_loader)
配置量化参数需要三个关键输入:
- 原始模型
- 量化配置
- 前向循环。
在此示例中,我们通过设置quant_cfg = mtq.NVFP4_DEFAULT_CFG对权重和激活使用默认的NVFP4配置,然后使用mtq.quantize()函数将其应用于模型。
# Quantize with NVFP4 config
quant_cfg = mtq.NVFP4_DEFAULT_CFG
model = mtq.quantize(model, quant_cfg, forward_loop=forward_loop)
成功应用量化后,可以使用本文的导出PTQ优化模型部分中的说明导出模型。
为了更深入地研究这种PTQ方法,我们建议您探索完整的Jupyter notebook演练。
高级校准技术
校准通过分析代表性输入数据来确定最佳比例因子。像max校准这样的简单方法使用张量中的最大绝对值,这可能会导致动态范围利用不足。更高级的技术(如SmoothQuant)平衡激活平滑度与权重缩放,而AWQ在训练后调整权重组以保持输出分布。
校准方法会显著影响量化模型的最终精度,并且应与工作负载的敏感性和延迟要求保持一致。
校准技术可以应用于浮点格式和整数格式。实际上,通常需要像INT8和INT4这样的整数数据类型才能恢复量化后的可接受精度。
激活感知权重量化
AWQ于2023年推出,侧重于通过考虑激活范围来进行权重量化。其思想是选择每个通道的权重比例,以最大限度地减少给定典型激活模式的最坏情况量化误差。
AWQ“容忍”一些对输出贡献较小的通道中的权重误差——因为激活较小。AWQ的优势之一是,它可以通过不平等地对待所有权重来实现非常低的位权重量化(4位),而影响最小。
图4 改编自AWQ论文——选择性缩放显著(高激活)权重以保持量化期间的精度
AWQ的核心前提是,它优先考虑显著权重——那些被认为最活跃的权重,通常是因为它们与高幅度激活对齐——并在量化期间更加小心地处理它们。这些关键权重要么以更高的精度量化,要么以其原生格式保留,而不太重要的权重则被更积极地量化。
这种选择性方法减少了在最重要的地方的量化误差,从而可以有效使用较低位格式。如图4所示,每个通道都根据平均幅度进行选择,并在量化之前仔细缩放,从而有助于保持最具影响力的权重的影响。
Model Optimizer API使用户能够覆盖诸如块大小之类的参数,以实现对量化过程的细粒度控制。有关完整的演练,请参阅min-max量化Jupyter notebook。
SmoothQuant
SmoothQuant于2022年推出,解决了低精度量化导致的激活异常值问题。在transformer架构中,层可能具有高度倾斜的激活分布(例如,由于Q/K/V的注意力计算规模,某些通道中的值非常大),这使得直接量化具有风险。
图5 改编自SmoothQuant论文——缩小激活比例并调整权重以保持数学有效性
图5显示了SmoothQuant过程的基本直觉。从激活的原始分布和相应的异常值|X|开始。这些值被缩小以创建

新媒网跨境认为,本质上,SmoothQuant通过将激活的量化难度转移到权重,从而使激活和权重更易于量化。
Model Optimizer AutoQuantize
Model Optimizer AutoQuantize函数是一种per-layer量化算法,它使用基于梯度的灵敏度分数来对每个层对量化的容忍度进行排序。这使其能够搜索和选择最佳量化格式——甚至跳过per-layer基础上的量化(图6)。
该过程受用户定义的约束的指导,例如effective_bits参数,该参数在更高的吞吐量需求与保持模型精度之间取得平衡。通过在layer级别定制量化,该算法可以积极地压缩不太敏感的层,同时在最重要的地方保持精度。用户还可以根据特定的硬件目标和模型要求应用不同级别的压缩,从而提供细粒度控制以优化跨不同环境的部署效率。
图6 AutoQuantize工作流程的简化动画——根据精度和性能权衡评估和选择最佳的per-layer量化格式(例如,INT8,NVFP4)
生成的模型将使用自定义量化方案,该方案根据提供给自动量化功能的候选配置应用。当per-layer的搜索空间很大时,与其他方法相比,此技术可能会导致更高的计算成本和更长的处理时间。为了降低复杂性,您可以选择一小组候选配置并跳过KV缓存校准。
使用Model Optimizer API应用AutoQuantize非常简单。它首先识别权重的量化配置池和激活的KV量化配置。随附的Jupyter notebook更深入地研究了不同的配置以及如何有效地应用它们。
量化为NVFP4的结果
前面的部分概述并初步介绍了各种PTQ技术的实现。每种技术的有效性(在生成的推理性能提升和模型精度方面)取决于所使用的确切配方和超参数。
NVFP4提供了Model Optimizer PTQ提供的最高级别的压缩,可提供稳定的精度恢复并显著提高模型吞吐量。下图8交叉绘制了从原始精度量化到NVFP4后对精度和输出令牌吞吐量的影响。
NVFP4量化显著提高了主要语言模型(例如Qwen 23B,DeepSeek-R1-0528和Llama Nemo Ultra)的令牌生成吞吐量,同时几乎保持了其所有原始精度,正如即使在2-3倍加速时也具有较高的相对精度百分比所证明的那样。
图8 交叉图显示了NVFP4令牌生成吞吐量加速和精度影响
以下聊天演示展示了对Deepseek-R1查询的响应的同等保真度,但与FP8基线相比,NVFP4量化模型响应速度更快。
图9 聊天演示比较了DeepSeek-R1响应——显示了同等的保真度,但与FP8量化相比,NVFP4量化的输出速度更快
性能提升和精度保持的结合使高效的TCO优化成为可能,而AI工作负载的保真度几乎没有变化。
导出PTQ优化模型
选择并成功应用所需的PTQ技术后,可以将模型导出到量化的Hugging Face检查点。这与常见的Hugging Face检查点类似,这使得跨各种推理引擎(例如vLLM,SGLang,TensorRT-LLM和Dynamo)共享,加载和运行模型变得容易。
导出到量化的Hugging Face检查点
from modelopt.torch.export import export_hf_checkpoint
export_hf_checkpoint(model, export_dir=export_path)
想立即尝试PTQ优化模型吗?查看Hugging Face Hub上的预量化模型检查点。NVIDIA Model Optimizer集合包括用于Llama 3,Llama 4和DeepSeek的即用型检查点。
新媒网跨境了解到,英伟达正在积极推动AI模型量化技术的发展和应用。
总结
量化是为模型推理增压的最有效方法之一——在延迟、吞吐量和内存效率方面取得了巨大的胜利,而无需重新训练。虽然当今大多数大型模型在FP16或BF16中运行(有些模型(例如DeepSeek-R1)在FP8中运行),但进一步推送到FP4等格式会释放出全新的效率水平。在这种技术的快速发展背后,是不断壮大的技术生态系统,这正在改变开发人员部署和扩展高性能AI的方式。
NVIDIA TensorRT Model Optimizer将此提升到了一个新的水平。通过支持诸如NVFP4(专为NVIDIA Blackwell GPU构建)之类的尖端格式、诸如SmoothQuant、AWQ和AutoQuantize之类的高级校准策略以及与PyTorch、Hugging Face、NeMo、Megatron-LM、vLLM、SGLang、TensorRT-LLM和Dynamo的无缝集成,为开发人员提供了一个强大的工具包,用于在不影响精度的情况下进行压缩。结果是什么?更快、更精简、更可扩展的AI部署,可保持精度并提升用户体验。如果您准备好了解这些优势的实际应用,请探索我们的Jupyter notebook教程或立即试用预量化的检查点。
风险前瞻与时效提醒:
- 合规性风险: 使用量化技术可能会影响模型的公平性和偏差,需要进行充分的测试和验证,确保符合相关的法律法规和伦理标准。
- 教程时效性: 随着技术的发展,本文所介绍的工具和方法可能会发生变化,请务必参考最新的官方文档和社区资源。
- 硬件兼容性: 不同的硬件平台对量化格式的支持程度不同,需要根据实际情况进行选择和优化。
新媒网(公号: 新媒网跨境发布),是一个专业的跨境电商、游戏、支付、贸易和广告社区平台,为百万跨境人传递最新的海外淘金精准资讯情报。















