 粤公网安备 44011302004783号
粤公网安备 44011302004783号 NVIDIA ProRL v2实测:3千步吃透LLM性能瓶颈!

大型语言模型(LLM)通过持续的强化学习(RL)能否不断提升性能,还是会达到瓶颈?这个问题无疑是当前人工智能领域最引人关注的焦点之一。英伟达(NVIDIA)研究团队开发的ProRL v2,正是为了探索LLM在长时间RL训练下的表现而设计的。它通过先进的算法、严格的正则化以及全面的领域覆盖,将RL训练推向了新的高度。
ProRL v2旨在系统地研究,当模型接受数千个额外的RL训练步骤后,是否还能取得显著的进步。现在,ProRL v2正式发布。接下来,我们将深入探讨其关键创新和先进方法,并分享ProRL v2的最新实验结果,揭示LLM如何持续学习和提升能力。
ProRL v2如何实现RL扩展?
思维链提示、树搜索等AI技术,能帮助模型更好地利用已有的知识。而RL,尤其是结合严格的、可编程验证的奖励机制,则有望将模型推向全新的领域。然而,传统的短程RL技术常常面临不稳定性和收益递减的问题,因此更多地被认为是“温度蒸馏”,而不是真正的能力扩展。
ProRL从根本上挑战了这一现状,它提供了以下关键特性:
- 扩展训练: 在五个不同的领域进行了超过3000个RL步骤的训练,在15亿参数的推理模型中实现了新的最佳性能。
- 稳定性和鲁棒性: 结合了KL正则化的信任区域、周期性的参考策略重置以及计划长度正则化。
- 完全可验证的奖励: 每个奖励信号都通过编程方式确定,并且始终可以验证。
- 强制简洁: 通过计划的余弦长度惩罚,确保输出保持简洁高效。
ProRL的目标不仅仅是重新采样已知的解决方案,而是真正扩展模型可以探索的范围。
| 特性 | 传统RL微调 | ProRL v2 |
|---|---|---|
| 训练步数和领域 | 几百步,一个领域 | 3000+步,五个领域 |
| 稳定性 | 熵崩溃,KL突增 | PPO-Clip, REINFORCE++-baseline, Clip-Higher, 动态采样, 参考重置 |
| 奖励模型风险 | 奖励模型漂移风险 | 完全可验证的奖励 |
| 输出简洁性 | 冗长、冗余的输出 | 计划的余弦长度惩罚 |
核心技术:ProRL算法和正则化
ProRL v2构建在REINFORCE++基线之上,利用Clip-Higher来鼓励探索,并使用动态采样来减少噪声并提高学习效率。此外,还引入了几项创新技术:
- 计划的余弦长度惩罚,用于生成简洁的输出。
- KL正则化的信任区域,并定期将参考重置为当前最佳检查点,以防止过拟合并确保稳定性。
带有REINFORCE++基线的近端策略优化
ProRL的核心是裁剪近端策略优化(PPO-Clip)损失,它通过限制新策略与旧策略的差异来稳定策略更新:
\mathcal{L}\mathrm{PPO}(\theta) = \mathbb{E}\tau\bigg[ \min\Big( r_\theta(\tau) A(\tau),\ \mathrm{clip}\big(r_\theta(\tau), 1 - \varepsilon_\mathrm{low}, 1 + \varepsilon_\mathrm{high}\big) A(\tau) \Big) \bigg]
其中:





这里的“group”指的是同一提示的所有生成响应(组归一化)。REINFORCE++基线中的全局批量归一化有助于防止由小组大小引起的值不稳定。它首先减去小组的平均奖励,以重塑奖励。因此,该算法对0(不正确)/ 1(正确)/ -0.5(格式奖励)或-1(不正确)/ 1(正确)/ -0.5(格式奖励)等奖励模式不敏感。然后,它应用全局批量归一化。
裁剪范围:\varepsilon_{\text{low}} = 0.20 \qquad \varepsilon_{\text{high}} = 0.28
Clip-Higher和动态采样
Clip-Higher使用PPO裁剪范围的更高上限,以减轻策略熵崩溃并促进采样多样性(
计划的余弦长度惩罚
为了促进简洁、token高效的输出,应用了计划的余弦长度惩罚:
\text{length_reward}(t) = \eta_{\min} + 0.5 \times (\eta_{\max} - \eta_{\min}) \times [ 1 + \cos ( \pi t / T ) ]
其中:
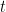
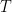


奖励更新:R'\tau = R{\text{correct}} + \lambda_\text{len} \cdot \eta_\text{len}(t)
惩罚以有规律的间隔循环开启和关闭(例如,100 次更新开启,500 次关闭),以平衡信息性和简洁性。
KL正则化和参考策略重置
KL惩罚使策略接近参考。定期重置有助于防止过度拟合并确保稳定性:
\mathcal{L}\mathrm{KL\text{-}RL} = \mathcal{L}\mathrm{PPO} - \beta, D_\mathrm{KL}(\pi_\theta\ |\ \pi_\mathrm{ref})
REINFORCE++基线中的KL散度使用
\mathcal{L}{k{2}} = \mathbb{E}{s \sim D,\ a \sim \pi{\theta_{\text{old}}}(\cdot|s)} \left( \frac{1}{2} ( -\log x )^2 \right)
其中:
[ x = \exp \left( \mathrm{clamp}\left( \log \frac{\pi_{\text{ref}}(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)}, -10, 10 \right) \right) ]
这里,函数

![[-10, 10]](https://s0.wp.com/latex.php?latex=%5B-10%2C+10%5D&bg=transparent&fg=000&s=0&c=20201002)
参考重置
每200-500个RL步骤(或在KL激增/验证停滞时),参考策略
定期应用的计划余弦长度惩罚也起着重要作用。通过循环开启和关闭惩罚,模型避免了陷入短或固定上下文长度的陷阱,使其能够提高输出的准确性和token效率。
总之,这两种策略可防止模型受到参考策略或上下文长度的限制,从而支持随着时间的推移在准确性和整体性能方面的持续改进。
关于扩展LLM的RL,我们发现了什么?
通过ProRL v2,我们观察到了以下突破:
- 新的最佳性能: 随着更多RL训练步骤的进行,性能不断提高,ProRL v2 3K为15亿参数的推理模型树立了新标杆。
- 持续的、非微不足道的改进: Pass@1和pass@k指标都在数千个RL步骤中攀升,扩展了基础模型的推理边界。
- 创造性和新颖的解决方案: ProRL输出显示与预训练数据的n-gram重叠减少,表明是真正的创新,而不是死记硬背。
- 边界突破: 在基础模型始终失败的任务中,ProRL不仅实现了强大的通过率,而且还展示了强大的分布外泛化能力。
ProRL综合结果
ProRL在数学、代码生成和各种推理Gym基准上进行了评估。报告的分数包括:
- 基础模型:DeepSeek-R1-Distill-Qwen-1.5B
- ProRL v1 2K:2,000 RL 步骤(使用 16K 上下文训练)
- ProRL v2 3K:3,000 RL 步骤(使用 8K 上下文训练)
截至撰写本文时,该模型仍在不断接受训练和准确性改进。下图说明了 2K 步模型相对于基础模型的性能增益,以及 3K 步模型相对于 2K 步模型的性能增益。即使训练上下文长度减半(16K 到 8K)——大大降低了计算成本——跨任务的整体模型准确性也得到了提高。
图 1. 在数学和 IFEVAL 基准测试的所有任务中,2K 步模型显着优于基础模型,3K 步模型进一步优于 2K 步模型
图 2. 在代码生成基准测试的所有任务中,2K 步模型显着优于基础模型,3K 步模型进一步优于 2K 步模型
图 3. 在推理 Gym 基准测试中,2K 步模型显着优于基础模型,3K 步模型进一步优于 2K 步模型
图 4. 数学任务中 3K 步模型的平均输出长度减少了 17.54%。
ProRL v2的实验数据表明,通过更长时间的强化学习训练,LLM在多个任务上都能够实现性能的持续提升。新媒网跨境获悉,尤其是在数学和代码生成等领域,ProRL v2展现出了显著的优势。这为跨境电商等领域的从业者,利用LLM来优化产品描述、客户服务、营销策略等提供了新的思路。
风险与合规性提醒:
- 数据安全: 在使用LLM进行跨境业务时,务必遵守相关国家和地区的数据安全法规,确保用户信息得到充分保护。
- 内容合规: 生成的文本内容需要符合目标市场的法律法规和文化习俗,避免出现违规或冒犯性内容。
- 算法偏见: 注意防范LLM可能存在的算法偏见,避免对特定群体产生歧视性影响。
教程时效性说明:
本文基于2025年的技术发展水平进行撰写,LLM技术发展迅速,相关算法和工具可能会不断更新。因此,请在实际应用中关注最新的技术动态,并根据具体情况进行调整。
新媒网跨境认为,ProRL v2的发布,为LLM的持续学习和性能提升提供了新的可能性。跨境从业者可以积极探索ProRL v2在自身业务中的应用,借助LLM的力量,提升效率、拓展市场。
新媒网(公号: 新媒网跨境发布),是一个专业的跨境电商、游戏、支付、贸易和广告社区平台,为百万跨境人传递最新的海外淘金精准资讯情报。















